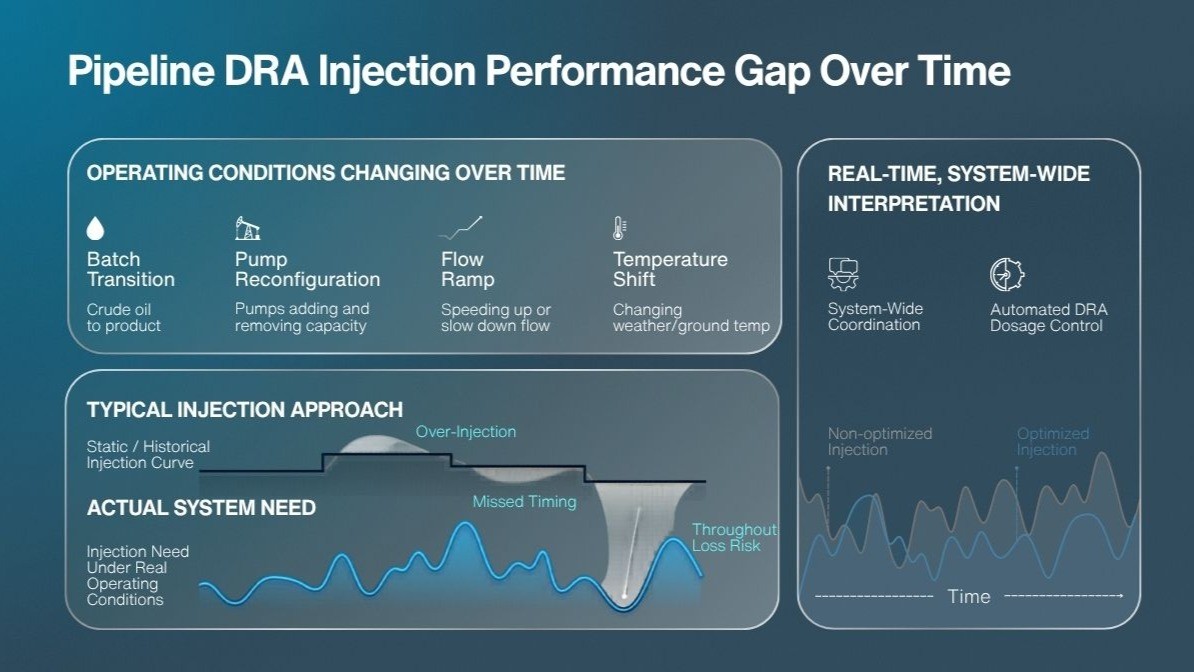
When "Normal" Becomes Unreliable
Risk Anomaly Detection & Operational Philosophy
The hardest part of anomaly detection is not finding anomalies.
It’s keeping the definition of normal from breaking.
Pipeline operations constantly change due to maintenance, upgrades, and operational decisions. Most anomaly detection systems allow models to drift continuously, which quietly erodes the baseline they depend on. Over time, this makes “normal” unreliable.
Baselines must be governed, not passively learned
At KartaSoft, we treat the baseline itself as a critical operational construct, one that must be actively governed.
We use operational events to control learning, not to label failures.
Maintenance activities, repairs, and asset changes are not training labels. They are signals that the operating state of the system has changed.
We use these events as state-change markers that tell the system:
- when to adapt
- when to pause learning
- when to reset or branch a baseline.
This prevents abnormal or transitional behavior from contaminating what the model considers normal.
When baselines drift, anomaly detection doesn’t just become noisy, it becomes operationally dangerous. Early indicators are missed, false alerts multiply after maintenance, and operators stop trusting the system. Once trust is lost, digital risk tools are sidelined long before they fail technically.
Baseline modeling comes first. Failure optimization comes later.
Instead of training directly on rare, noisy failure data, we first build clean, stable baselines for each operating regime.
Only after those baselines are established do we use integrity outcomes to tune sensitivity and prioritization. This preserves broad sensitivity to unexpected behavior without turning the system into a brittle failure classifier that only recognizes what it has already seen.
The system knows the difference between “something changed” and “something is wrong.”
Knowing the difference between change and fault
Post-maintenance behavior, instrumentation updates, and genuine anomalies look very different in practice. Our approach explicitly encodes this distinction, which dramatically reduces false alerts, improves interpretability, and builds operator trust.
Ours is decision support, and not automated control. KartaSoft’s insights produce context-aware anomaly signals designed for engineering review and triage. It complements existing SCADA alarms and fits naturally into safety-critical workflows where human judgment remains essential. Importantly, this approach commercially scales where traditional machine learning breaks.
Why this approach is deployed in the real world
Because the system does not rely on exhaustive failure labeling and explicitly handles non-stationary operations, validation is measured in weeks, not years.
A typical validation journey takes 8–12 weeks across diverse assets and long operational histories. That makes the approach deployable, defensible, and operationally realistic, without simplifying the problem it is meant to solve.
Governing the baseline is what makes the difference.

.jpg)